pytorchのお勉強(6):GPUの利用
はじめに
Pytorchのお勉強の続きです。
前回までに学んだ内容でDeepNeural Networkでやりたい一通りの事はできるようになりましたが、肝心のGPUを用いた高速化を学んでいませんでした。
GPUはGraphic Processing Unitと呼ばれる並列計算が得意な演算装置です。
ゲームやグラフィック・ツールを高速に動作させる為に作られた外部演算装置であり、CPUで構成されたホスト計算機にくっつけて動作させます。
現在では並列演算の性能の高さを活かし、Deep Learningや物理シミュレーションなどの科学計算や、仮想通貨のマイニングなどにも応用されています。
今回は、pytorchの学習、推論にGPUを用いる方法を学んでいきます。
この公式ドキュメントを参考に進めていきます。
GPUが使えるか確認
GPUを学習に用いるためには、以下を満たしている必要があります。
1.ホストPCにGPU(Nvidia推奨)を接続する
2.GPUのドライバをインストールする
3.condaでcudatoolkitを導入する
これらについては実験環境のOS名とNivida Driverで検索すると参考になる資料が沢山出てくると思います。
これらが導入済とした時、次のコードを実行することでPytorch上でGPUが使用可能か確認できます。
device = "cuda" if torch.cuda.is_available() else "cpu" print("Using {} device".format(device))
GPUが使える状態だと
Using cuda device
と出力されます。
学習にGPUを使う
公式ドキュメントによると「学習データとネットワークモデルをGPUで使いますよ!」と宣言すれば、簡単にGPUで学習できるみたいです。
# ネットワークモデルをGPUで利用する事を宣言する import torch device = "cuda" if torch.cuda.is_available() else "cpu" model = Network() model = model.to(device)
# データをGPU上に展開する事を宣言する def batch in dataloader: X = batch["image"].to(device) Y = batch["label"].to(device) pred = model(X)
dataloaderに関しては過去の記事を参照してください。
nsr-9.hatenablog.jp
非常に簡単に利用できますね!
実際にGPUを使ってみる
前回作成した学習用のコードをGPUに対応させます。
nsr-9.hatenablog.jp
変更点はnetwork modelとbatchに関してGPUで使うことを宣言している部分だけです。
from dataset import CustomImageDataset from network import Net import torch from torch.utils.data import DataLoader import torchvision.models as models device = "cuda" def train_loop(dataloader, model, loss_fn, opt): data_size = len(dataloader.dataset) for batch, D in enumerate(dataloader): X = D["image"].to(device) y = D["label"].to(device) pred = model(X) loss = loss_fn(pred, y) # バックプロパゲーション opt.zero_grad() loss.backward() opt.step() if batch % 100 == 0: loss, current = loss.item(), batch*len(X) print(f"loss: {loss:>7f} [{current:>5d}/{data_size:>5d}]") if __name__ == "__main__": loss_fn = torch.nn.CrossEntropyLoss() model = Net().to(device) optimizer = torch.optim.Adam(model.parameters()) train_data = CustomImageDataset() train_dataloader = DataLoader(train_data, batch_size=128, shuffle=True) epochs = 20 import time start = time.time() for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train_loop(train_dataloader, model, loss_fn, optimizer) #input_image = torch.zeros((1, 1, 64, 64)) #onnx.export(model, input_image, "model.onnx") print("time: "+str(time.time()-start)) torch.save(model, "model.pth")
コードの先頭の方にあるdevice="cuda"を"cpu"に変更すると、CPUで学習できるようになります。
GPU/CPUでそれぞれ20 epoch学習させた際の学習時間は次のようになりました。
| device | 学習時間(秒) |
|---|---|
| CPU | 78 |
| GPU | 68 |
学習時間が12%くらい削減されていますね。
普段使ってるライブラリとタスクではGPUを用いると劇的に学習時間が改善されるのですが、あまり改善効果が見られませんね。
こうなった理由としては、ネットワークの規模が小さい(計算コストが小さい)事と、入力画像が比較的小さい(32x32pix)事が挙げられます。
計算量が小さいとGPUの並列効果よりも、GPUメモリへのデータ転送に時間がかかってしまう事があります。
計算量の多いタスクで改善効果を確認してみたいですね。
また、GPUで学習を行っている際に、別のターミナルから以下のコマンドを実行すると、GPUの状態を確認することができます。
nvidia-smi
上記の学習を行っていた際の出力は次のようになります。
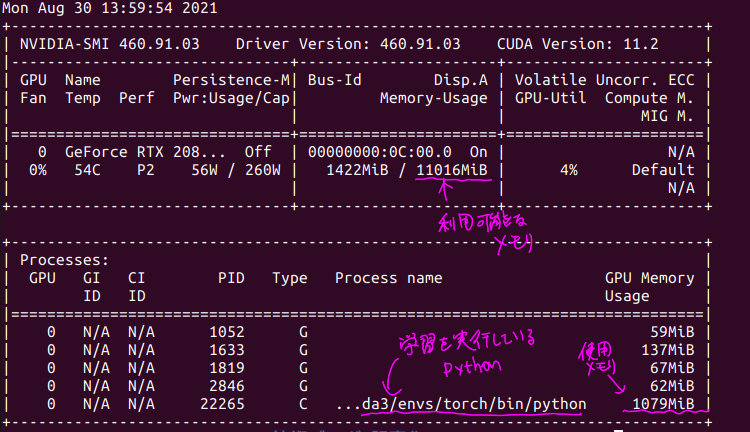
GPUのメモリが1GByte程度だったので、結構昔のGPUでも学習することができそうですね。
まとめ
今回はpytorchでGPU学習する方法を勉強しました。
pytorchは非常に簡単にGPU学習とCPU学習を切り替えられるのでとても便利だと思いました。(他のライブラリだとこうはいかない)
今回は小さいタスクだったのでGPU利用による改善効果が小さかったのですが、次は大きなタスクで実験してみたいと思います。