PytorchによるImage Segmentation(2)
はじめに
nsr-9.hatenablog.jp
この記事の続きです。
Pytorchを用いてU-NetのImage Segmentationをやっていきます。
前回はU-Netのモデルを定義したので、今回はDataLoader部分を作っていきます。
Image Segmentation用のDataset
Image Segmentationを簡単に表現すると、CNNで自動的に色塗りをさせるようなイメージです。
車や人が写ってる領域や、医療画像の血管領域だけ色塗りさせたり等、かなり器用にタスクをこなしてくれます。
Image Segmentationを学習する際は、画像と色塗りした模範画像(ラベル)のペアを100枚から数万枚単位で用意します。 以下に入力データの参考例として、cityscapes dataset[1]のデータを載せます。
| 入力画像の参考例 | 模範画像の参考例 |
|---|---|
 |
 |
学習に必要な枚数はターゲットとなるタスクの難しさによって増減しますが、大体1000枚あればそれなりの精度が出ます。
また、ラベル画像はアノテーションツールを用いて作成します。
数年前はLabelMeというアノテーションツールしかなかったのですが、昨今では様々なアノテーションツールが公開されているようですね。
セマンティック・セグメンテーション用アノテーションツール – demura.net
今回は、ラベル画像を位置から作るのではなく、オープンに公開されているCityscapes Datasetを加工して、Image Segmentation用のデータセットを作成しました。 Cityscapes Datasetは道路や空、街路樹、歩行者など様々な対象物を色分けしたMulti-classのSemantic Segmentation Datasetなのですが、車のみを対象としたImage Segmentation Datasetにします。
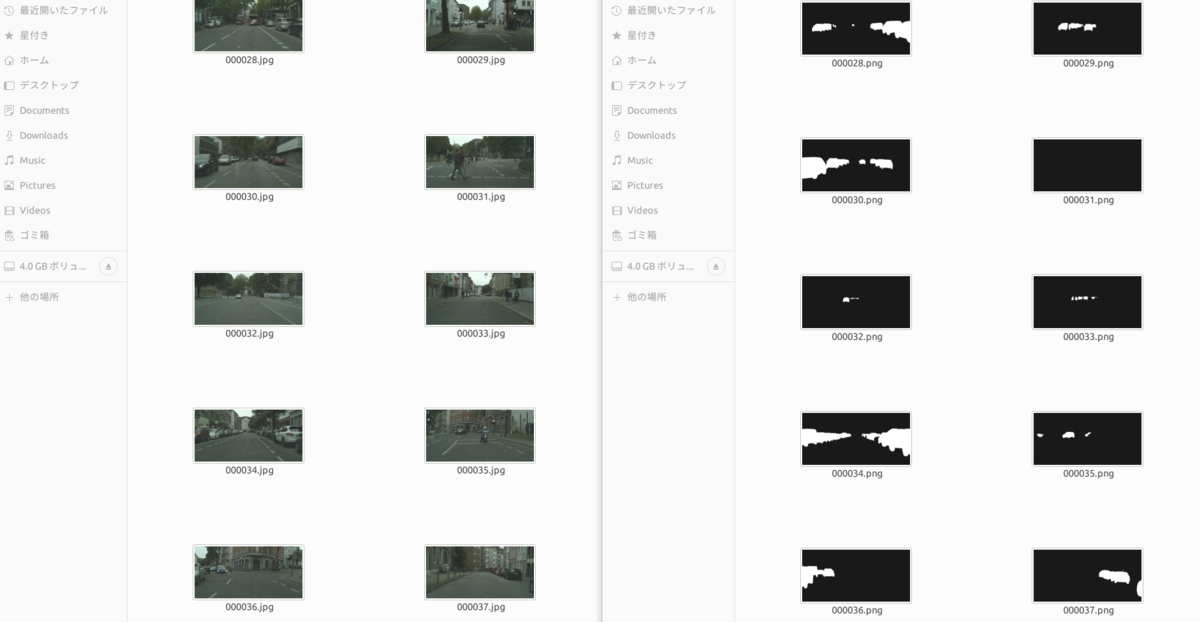
入力画像をimages/、ラベル画像をlabels/にした際のDataLoaderは次のようになりました。
import os import torch from torch.utils.data import Dataset from torchvision.io import read_image, write_jpeg import glob from torch.utils.data import DataLoader from torchvision import transforms as transforms import numpy as np class CustomImageDataset(Dataset): def __init__(self, train=True): self.train = train if train: self.image_path = glob.glob("./dataset/train/images/*.jpg") self.label_path = glob.glob("./dataset/train/labels/*.png") else: self.image_path = glob.glob("./dataset/val/images/*.jpg") self.label_path = glob.glob("./dataset/val/labels/*.png") self.image_path.sort() self.label_path.sort() self.gray = transforms.Grayscale() self.resize = transforms.Resize((320, 640)) def __len__(self): return len(self.image_path) def __getitem__(self, idx): img_path = self.image_path[idx] label_path = self.label_path[idx] image = read_image(img_path) label = self.gray(read_image(label_path)) # 車以外のラベルを0にする label[label != 25] = 0 label[label == 25] = 1 image = self.resize(image) label = self.resize(label) # ランダムで左右にフリップする if torch.randn(1) > 0: image = transforms.functional.hflip(image) label = transforms.functional.hflip(label) # ランダムで256x256をクロッピングする i, j, h, w = transforms.RandomCrop.get_params(image, (256, 256)) image = transforms.functional.crop(image, i, j, h, w) label = transforms.functional.crop(label, i, j, h, w) label = torch.nn.functional.one_hot(label[0].long(), num_classes=2) label = torch.permute(label, (2, 0, 1)) sample = {"image": image.float(), "label": label.float()} return sample if __name__ == "__main__": bsize = 8 train_data = CustomImageDataset() train_dataloader = DataLoader(train_data, batch_size=bsize, shuffle=True) data = next(iter(train_dataloader)) images = data["image"] labels = data["label"] for i in range(bsize): image = images[i] label = labels[i] label = torch.stack([label[1], label[1], label[1]]) print(label.size()) write_jpeg(image.to(torch.uint8), "image_{0:01d}.jpg".format(i)) write_jpeg(label.to(torch.uint8)*255, "label_{0:01d}.jpg".format(i))
このデータローダーを走らせると、次のような学習バッチが生成されます。
| image | label |
|---|---|
 |
 |
入力画像に対応したラベル画像が生成されていますね!
まとめ
今回はImage Segmentation Datasetを読み込むDataloaderを作成しました。
次回はU-Netを学習させるLoss Fuctionを実装し、学習を行ってみたいと思います。
[1] Cityscapes Dataset – Semantic Understanding of Urban Street Scenes