pytorchのお勉強(3):オリジナルのデータセット読み込み
はじめに
pytorchのお勉強の続きです。 今回は学習するデータセットを読み取る所を学びます。
pytorchでCNNの学習システムを開発する際の全体像を以下に示します。
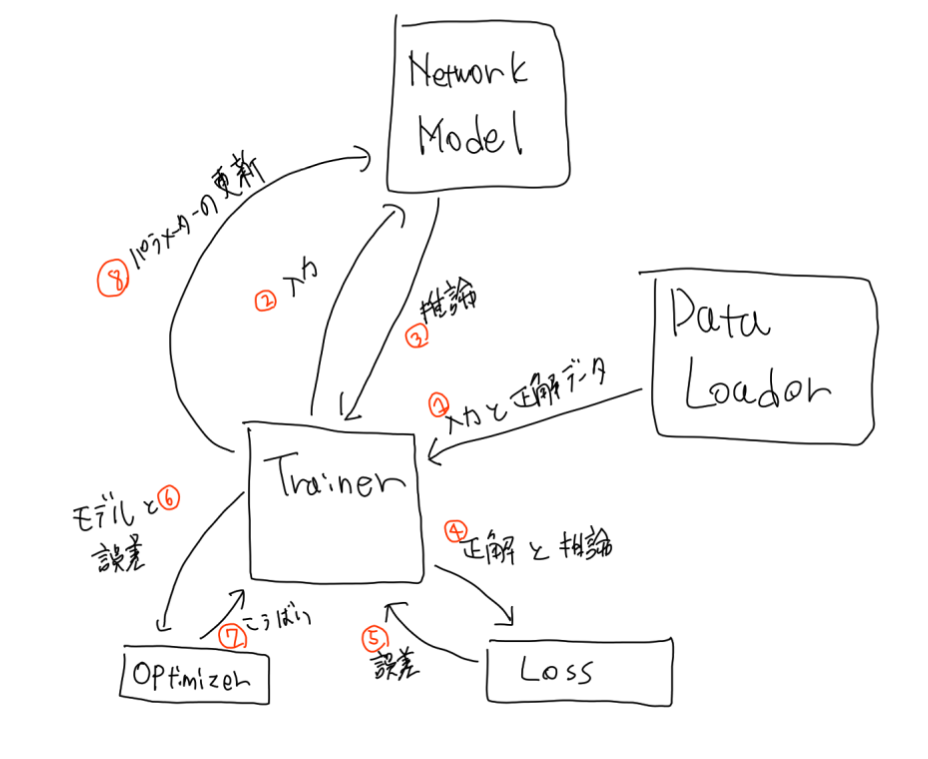
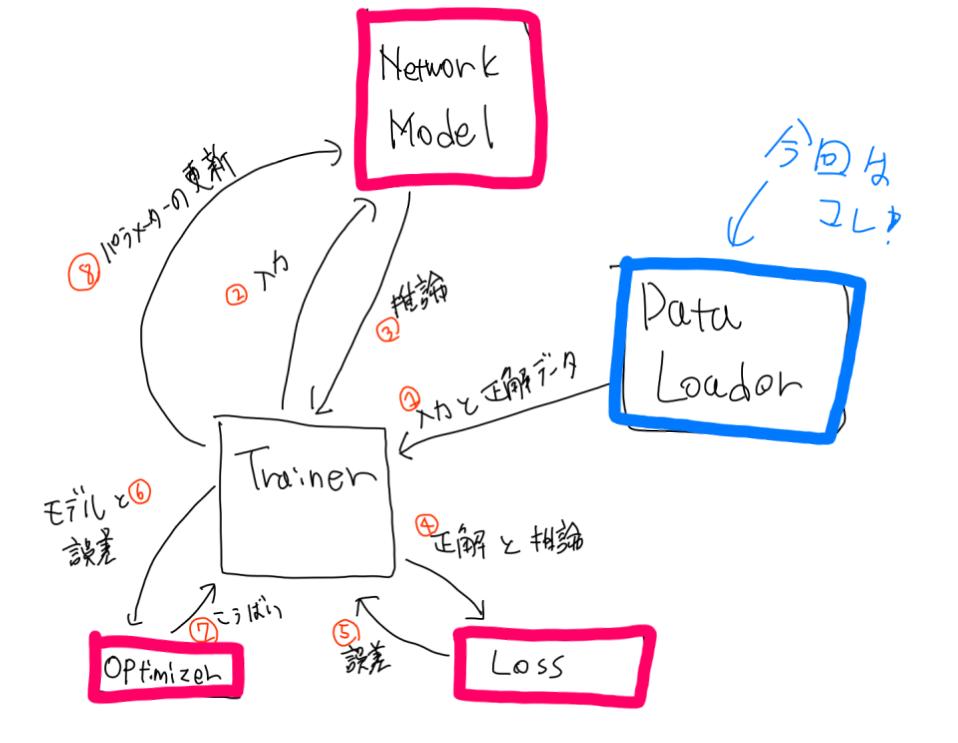
この画像で言うと、ピンクで囲った部分が前回までに勉強した部分で、青色の囲った部分が今回勉強する所です。
カスタムデータセットの作成方法
今回はデータセットに関するチュートリアル資料を参考にします。
pytorchでデータセットを扱う際には、DataLoaderクラスとDatasetクラスを用います。
これら2つのクラスを活用することで、データセットに関する実装を学習システムから切り離すことができ、メンテナンスが向上します。
Datasetクラスには入力データとそれに対応する正解データが格納されており、DataloaderクラスはDatasetクラスがイテレーションできるように管理する機能が実装されています。
Datasetクラスの作り方
Datasetクラスを作る際には、init, len, getitemの3つの関数を実装する必要があります。
以下に疑似コードを記載します。(注意:このままだと動きません)
import os from torchvision.io import read_image class CustomImageDataset(Dataset): def __init__(self, annotations_file, img_dir, transform=None, target_transform=None): # Datasetオブジェクトがインスタンス化される際に1回だけ実行される # 画像のディレクトリなどを初期化する pass def __len__(self): # データセットのサンプル数を返す return 1000 def __getitem__(self, idx): # 指定されたidxに対応するサンプルデータを読み出して返す # ラベルも一緒に返す img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0]) image = read_image(img_path) label = self.img_labels.iloc[idx, 1] sample = {"image": image, "label": label} return sample
これを参考にオリジナルデータセットを読み込むDatasetクラスを作成します。
手元にいい感じのデータセットがなかったので、Githubからいい感じの規模感のデータセットをお借りしました。※
GitHub - harveenchadha/Udacity-CarND-Vehicle-Detection-and-Tracking: Term 1, Project 5 - Udacity Self Driving Car Nanodegree
※ライセンスの記載が見当たらなかったので、個人の研究利用ということで具体的なコードや詳細な画像等は載せないようにします
dataフォルダ以下に、データセットを展開しました。
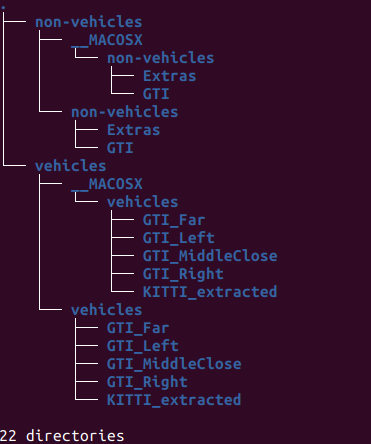
このデータセットは64x64[pix]の車両の背面画像(vehicle)と64x64[pi]のそれ以外の画像(non-vehicle)で構成されています。
画像サイズがそれなりに小さいのにデータ数は合計で18000枚以上あるため、DNNの勉強には持ってこいな規模感になっています。
CustomDatasetクラスを以下のように改造しました。
import os import torch from torch.utils.data import Dataset from torchvision.io import read_image import glob from torch.utils.data import DataLoader class CustomImageDataset(Dataset): def __init__(self): self.negative_path = glob.glob("./data/non-vehicles/**/**/*.png") self.positive_path = glob.glob("./data/vehicles/**/**/*.png") def __len__(self): return len(self.negative_path) + len(self.positive_path) def __getitem__(self, idx): if idx < len(self.negative_path): img_path = self.negative_path[idx] label = torch.Tensor([1, 0]) else: idx = idx - len(self.negative_path) img_path = self.positive_path[idx] label = torch.Tensor([0, 1]) image = read_image(img_path) sample = {"image": image, "label": label} return sample
globライブラリはディレクトリを走査しながらファイルを読み込めるので非常に便利です。
使い方は以下を参照してください。
Pythonで条件を満たすパスの一覧を再帰的に取得するglobの使い方 | note.nkmk.me
DataLoaderクラスの作り方
DataLoaderクラスはDatasetが読み込んだ学習データからミニバッチを作成するクラスです。
基本的にはIteratorの様な振る舞いをします。
from torch.utils.data import DataLoader train_data = CustomDataset() dataloader = DataLoader(train_data, batch_size=64, shuffle=True) for i in range(10): data = next(iter(dataloader)) img = data["image"] label = data["label"] print(img.size(), label.size())
出力は次のようになります。
torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2]) torch.Size([64, 3, 64, 64]) torch.Size([64, 2])
batchサイズが64の64x64[pix]のRGB画像と、batchサイズが64の2次元のOne-Hot-Vectorが生成されていますね!
まとめ
pytorchのDatasetクラスとDataLoaderクラスの使い方を学び、オリジナルのデータセットを読み込めるようになりました。
次回こそはこのDatasetクラスを用いてNeural Networkを学習してみたいと思います。