PytorchによるImage Segmentation(3)
はじめに
PytorchによるU-NetのImage Segmentationの続きです。
前回はDataLoader部分を実装したので、今回はLoss Functionを実装して実際に学習、推論をやっていきます。
Image SegmentationのLoss Function
2クラスのImage Segmentationは、普通のCategorical Cross EntropyなどのLoss関数ではうまく学習できない事が多いです。
分類するクラス(例えば車両と背景)のピクセル数の出現頻度が極端に偏ってしまう事が原因です。
Cityscapesから適当に画像を参照し、車両と背景のピクセル数をカウントすると、次のようになります。
| 入力ラベル | 出現頻度 |
|---|---|
 |
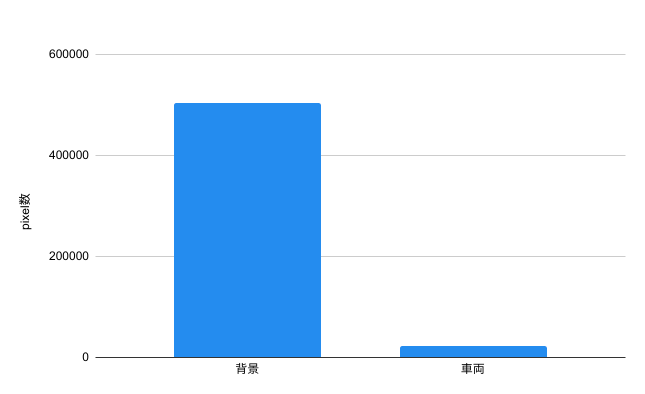 |
車両と背景では出現頻度が20倍近く異なります。
この様に出現頻度が大幅に偏っている状態だと、「全部背景カテゴリである!」と適当に推論してもそれなりに正解になってしまい、うまく学習を進める事ができません。
その様なアンバランスな状態を解消するLoss関数がDice Loss Function[1]です。
Dice Lossは次のような式で表されます。
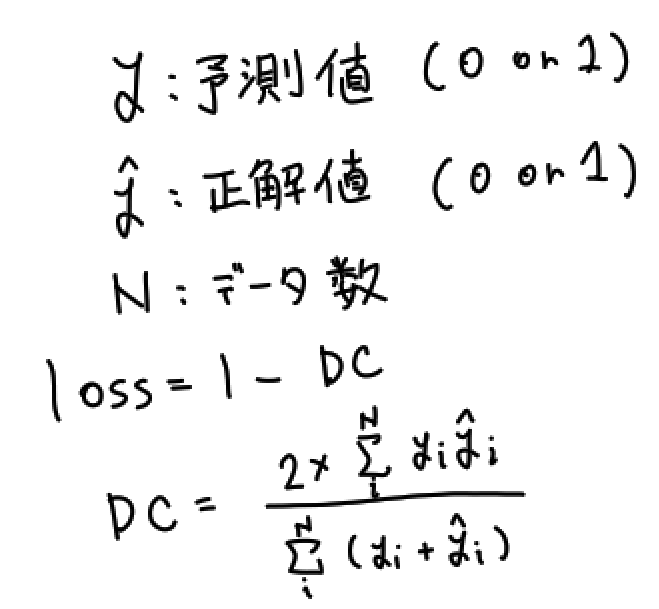
直感的な表現をすると、予測値または推測値に1が含まれる(車両に関係する)ピクセルのみを使ってLoss値を求めています。
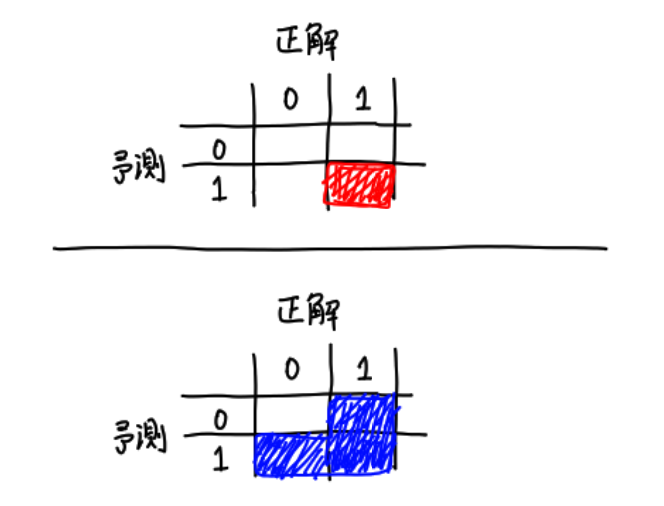
こうすることで大多数を占める予測値も推測値も背景であるピクセルを評価から除外する事ができるので、「とりあえず全部背景!」という適当な推論をしても正解にならなくなります。
Dice Loss Functionですが、いい感じに実装を公開してくれている方がいらっしゃったので、今回はそちらを参考に実装しました。
pytorch-unet/loss.py at master · usuyama/pytorch-unet · GitHub
from torch import nn import torch.nn.functional as F import torch def dice_loss(pred, target, smooth = 1.): pred = pred.contiguous() target = target.contiguous() intersection = (pred * target).sum(dim=2).sum(dim=2) loss = (1 - ((2. * intersection + smooth) / (pred.sum(dim=2).sum(dim=2) + target.sum(dim=2).sum(dim=2) + smooth))) return loss.mean() def calc_loss(pred, target, metrics=None, bce_weight=0.5): # Dice LossとCategorical Cross Entropyを混ぜていい感じにしている bce = F.binary_cross_entropy_with_logits(pred, target) pred = torch.sigmoid(pred) dice = dice_loss(pred, target) loss = bce * bce_weight + dice * (1 - bce_weight) return loss
U-Netの学習
Networkモデル、DataLoader、Loss Functionを実装できたので、いよいよ学習させていきます。
学習のコードは次のようになります。
from dataset import CustomImageDataset from network import UNet import torch from torch.utils.data import DataLoader import torchvision.models as models import os from losses import FocalLoss, calc_loss import matplotlib.pyplot as plt device = "cuda" def train_loop(dataloader, model, loss_fn, opt): data_size = len(dataloader.dataset) for batch, D in enumerate(dataloader): X = D["image"].to(device) y = D["label"].to(device) opt.zero_grad() pred = model(X) loss = loss_fn(pred, y) # バックプロパゲーション loss.backward() opt.step() if batch % 100 == 0: loss, current = loss.item(), batch*len(X) print(f"loss: {loss:>7f} [{current:>5d}/{data_size:>5d}]") if __name__ == "__main__": #loss_fn = FocalLoss(1) #loss_fn = torch.nn.CrossEntropyLoss() loss_fn = calc_loss model = UNet(2).to(device) #model = torch.load("model.pth") optimizer = torch.optim.Adam(model.parameters()) train_data = CustomImageDataset() train_dataloader = DataLoader(train_data, batch_size=16, shuffle=True, num_workers=os.cpu_count()) epochs = 100 import time start = time.time() for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train_loop(train_dataloader, model, loss_fn, optimizer) print("time: "+str(time.time()-start)) torch.save(model, "model.pth")
DataLoader(train_data, batch_size=16, shuffle=True, num_workers=os.cpu_count()
ここのnum_workersでCPU数を指定する事で、DataLoaderを並列処理にすることができます。
Image Segmentationの様に画像が大きく読み込み時間がボトルネックになる場合や、計算量の多いData Augmentationを行う場合は並列処理にすることで大幅に実行時間を短縮する事ができます。
学習を開始するとGPUのファンが高速回転し始め、電気をモリモリ消費していきます。
数時間くらいで学習が終わるのですが、もっと大規模な学習を行った時の電気代が非常に気になるところです。
推論結果
学習後のモデルを使って色々な画像を推論してみました。
推論コードは次のようになります。
import torch from torchvision.io import read_image import sys from torchvision import transforms as transforms import numpy as np model = torch.load("./model.pth") def run(path): img = read_image(path).float().to("cuda") resize = transforms.Resize((320, 640)) img = resize(img) out = model(img[None,]) out = torch.nn.functional.sigmoid(out) out = out.detach().to("cpu") out = torch.argmax(out[0], axis=0) out = out.numpy() plt.imshow(out) plt.show() if __name__ == "__main__": while True: path = input()[1:-2] run(path)
Cityscapesの評価画像を推論すると次のようになります。
| 入力画像 | 推論画像 |
|---|---|
 |
 |
 |
 |
 |
 |
概ね正しく推論できていそうですね!
また、Cityscapesにはdemo用のビデオがあるので、そちらに対しても推論してみました。
わかりやすくする為に推論結果を青色にして、入力画像に重ねてみました。



まとめ
PytorchでImage Segmentation手法であるU-Netを実装し、Cityscapes Datasetを用いて車両のバイナリSegmentationを学習、推論しました。 Image Segmentationは様々な画像処理技術へ応用が可能なので、今後はこの技術を使って色々作っていきたいと思います。
[1] Sudre, Carole H., et al. "Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations." Deep learning in medical image analysis and multimodal learning for clinical decision support. Springer, Cham, 2017. 240-248.