pythonで音声信号のリアルタイムプロット
やりたいこと
pydubで読み込んだ音声信号に対し、Sliding Windowをしながら波形をプロットしたい。
音声信号処理を行う場合は、読み込んだ信号全体に対して一気に処理を施すのではなく、短い時間の区間ごとに処理を施すそうです。
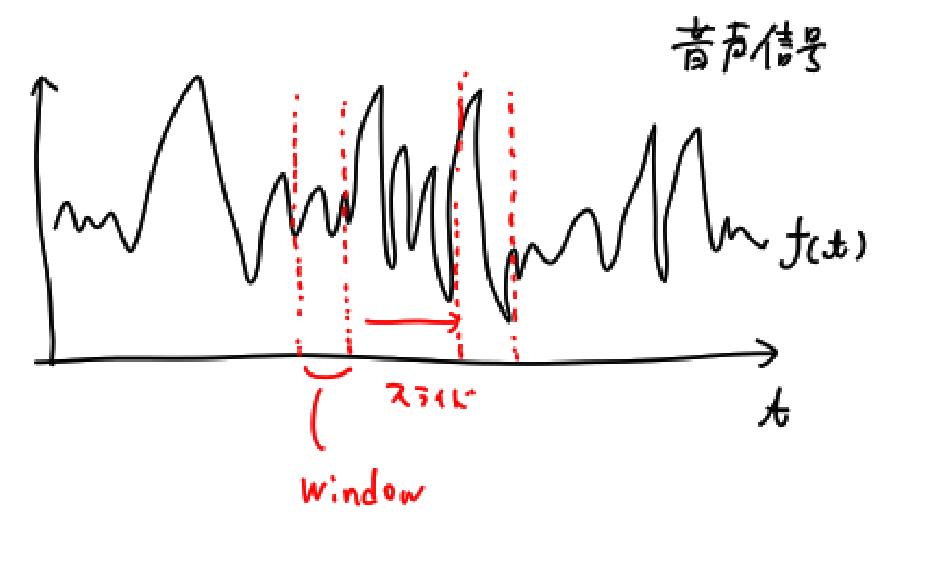
Computer Visionで言うならば、信号全体に対する処理が大局的画像処理にあたり、短い区間に区切った処理が局所的画像処理やSliding Windowになるのでしょうか?
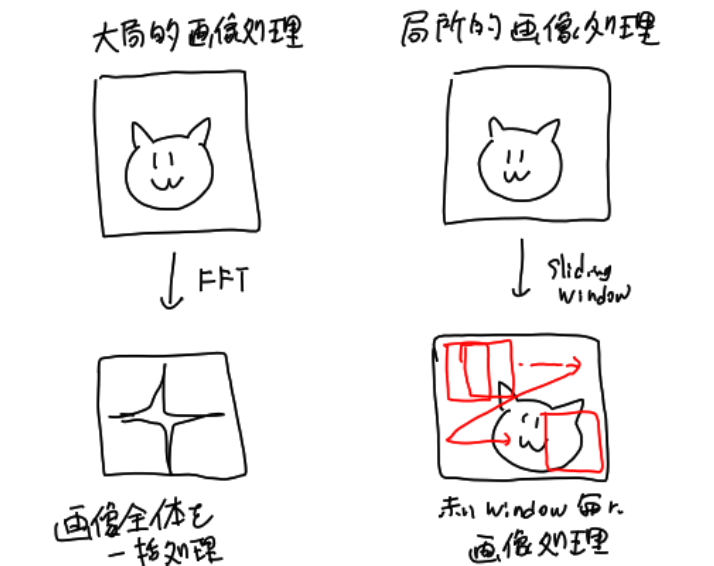
音声波形は時間毎に性質が異なっていくはずなので、局所的な処理を施すのは納得が行きますね。
音声信号のSliding Window
音声信号の読み込みは前の記事を参照してください。
読み込み部分だけ抜粋すると次のようになります。
import pydub import numpy as np from pydub import AudioSegment song = AudioSegment.from_wav("audio.wav") song_array = np.array(song.get_array_of_samples()) song_ch1 = song_array[::2] song_ch2 = song_array[1::2]
song_arrayがwavファイルを時系列信号に変更したものです。
今回の音源はLeftとRightマイクの2ch入力であるため、song_ch1, song_ch2と信号を分離しています。
sliding windowはnumpy 1.20で標準に扱えるようになっていますが、今回はわかりやすさを重視し、for文で実装します。
区間幅をwsizeとした時のsliding window処理は次のようになります。
wsize = 64 for index in range(song_ch1.shape[0]//wsize): data = song_ch1[index*wsize: (index+1)*wsize]
簡単ですね。
このfor文の中でグラフの描画を行っていきます。
コード全体は次のようになりました。
import pydub import numpy as np from pydub import AudioSegment import matplotlib.pyplot as plt if __name__ == "__main__": song = AudioSegment.from_wav("audio.wav") song_array = np.array(song.get_array_of_samples()) song_ch1 = song_array[::2] song_ch2 = song_array[1::2] wsize = 64 fig, ax = plt.subplots(1, 1) vmax, vmin = 0, 0 for index in range(song_ch1.shape[0]//wsize): data = song_ch1[index*wsize: (index+1)*wsize] x = np.arange(index*wsize, (index+1)*wsize) vmax = max(vmax, data.max()) vmin = min(vmin, data.min()) ax.set_xlim((x.min(), x.max())) ax.set_ylim((vmin, vmax)) if index == 0: lines, = ax.plot(x, data) else: lines.set_data(x, data) # リアルタイム描画したい場合 plt.pause(.05) # 保存したい場合 # plt.savefig("./out/fig_{0:06d}.jpg".format(index))
実行結果
適当な音源に対してグラフプロットした結果を以下に示します。
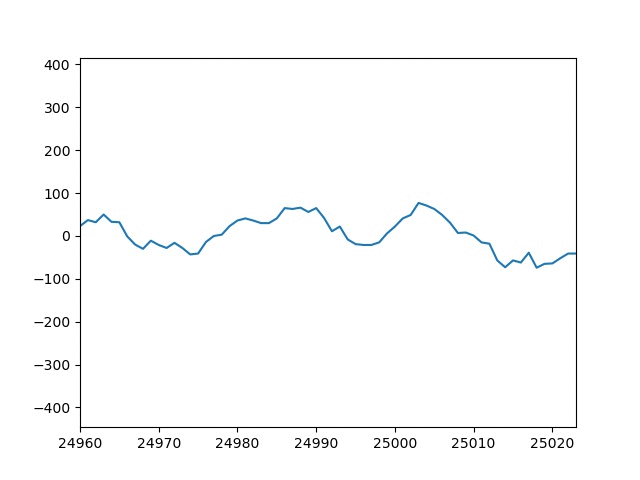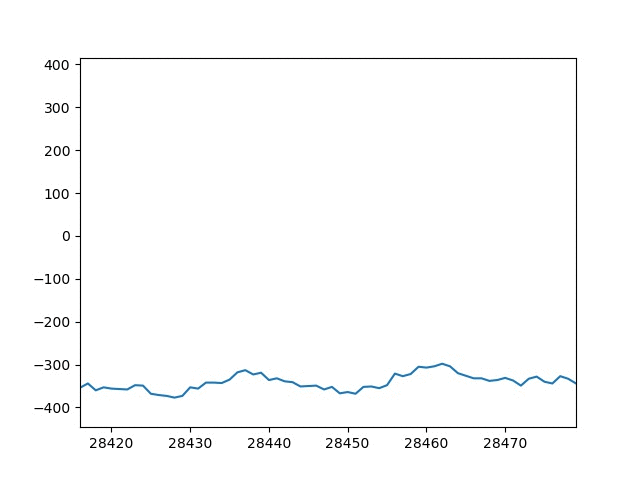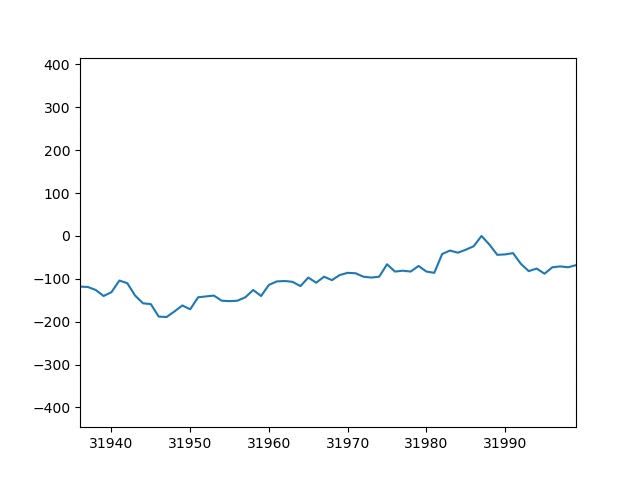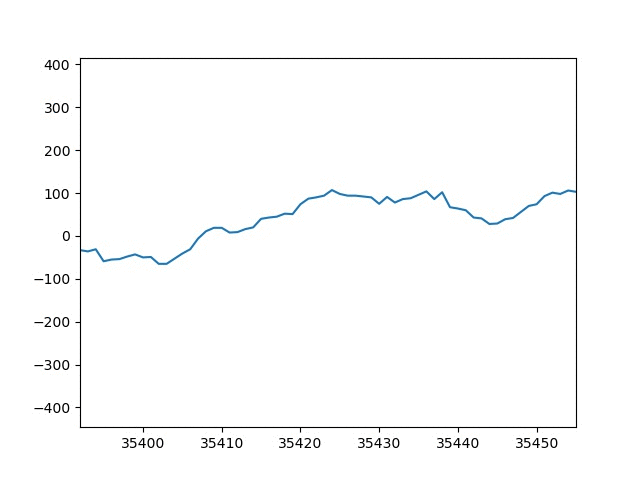
思ったよりgifアニメーションが早くて確認する事が難しいですね。
以下に適当なタイミングのグラフ画像を添付します。
| t=390 | t=391 |
|---|---|
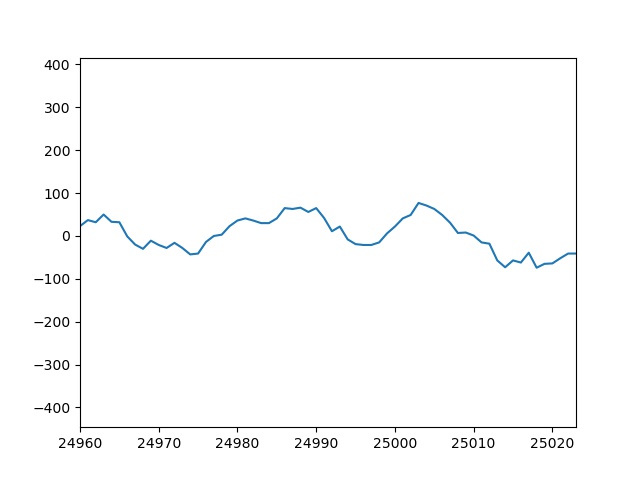 |
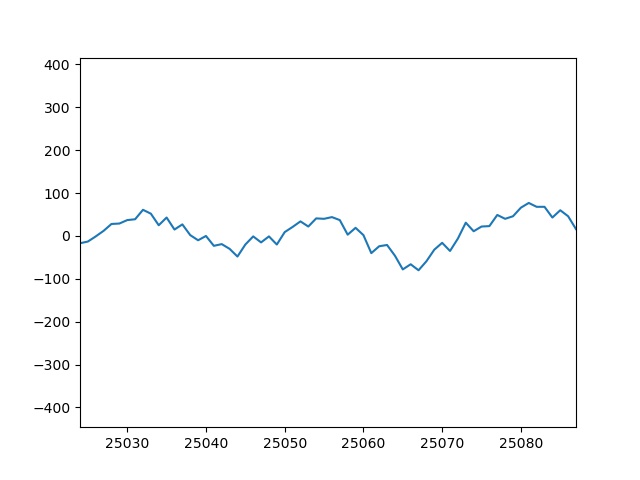 |
t=390の画像のx軸を見ると開始点が24960、終了点が25020になっています。
今回はWindow幅を64にしたので、390×64=24960で開始点が一致していることがわかります。
おわりに
音声信号を区間単位でグラフ表示する事が出来るようになりました。
次回はこの区間データに対してなにか処理を行ってみたいと思います。