射影ヒストグラムを用いた文書画像の回転補正
文書画像の回転補正
tesseractは優れたOCRですが、回転ロバスト性に課題があります。
その為、実応用を行う際には文書画像の回転角を推定し、補正してあげる費用があります。
文書画像の回転補正は多くの方が研究されており、多種多様な手法が提案されています。
その中でも今回は、射影ヒストグラムを用いた手法を用いて、文書画像の回転角を推定してみます。
射影ヒストグラム
射影ヒストグラムは文書画像のレイアウト解析によく使われます。
2値化された文書画像に対し、縦書きなら縦方向、横書きなら横方向に輝度値の総和を取ります。
以下、特に断りがない場合、横書きについて扱います。
文書画像が「文字と背景で構成される」ことと「平行した行で構成される」という2つの仮定を置くことで、輝度値の総和から簡単に行を抽出できます。
これに関しては、具体的なデータを見たほうが理解しやすいので、以下に文書画像と射影ヒストグラムの結果を示します。
| 文書画像 | 射影ヒストグラム |
|---|---|
 |
 |
行と射影ヒストグラム(青いヒストグラム)が一対一に対応しているように見えます。
このヒストグラムのまとまり部分をうまく扱うことで、文書画像の中から行を抽出する事ができます。
以下に、射影ヒストグラムを求めるコードを示します。
import cv2 import numpy as np import sys def projection_histogram(bimg): bimg[gray == 255] = 1 bimg = np.ones_like(bimg) - bimg out = np.sum(bimg, axis=1) return out if __name__ == "__main__": img = cv2.imread(sys.argv[1], 0) bimg = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 9, 10) hist = projection_histogram(bimg) print(hist)
射影ヒストグラムと文書画像の回転
文書画像が回転していない場合、射影ヒストグラムと行は一対一の対応関係を持ちますが、文書画像が回転している場合はその関係が崩れます。
以下に回転させた場合の射影ヒストグラムを示します。
| 回転無し | 回転1 | 回転2 |
|---|---|---|
|
 |
 |
文書画像が回転すると射影ヒストグラムが仮定していた平行性の仮定が崩れるため、行との対応関係が崩れています。
射影ヒストグラムの平行性に基づいた文書画像の回転推定
文書画像が回転すると平行性の仮定が崩れる為、行が抽出できないことがわかりました。
これを逆に考えると射影ヒストグラムで行が抽出できる時、その文書画像は正面を向いている(平行性が仮定できる)と考えられます。
すなわち、ある回転角で撮影された文書画像が与えられた時、その文書画像を回転させながら射影ヒストグラムを求めることで、正面画像が得られます。
以下に、アルゴリズムを示します。 1. 文書画像を2値化する 2. 文書画像を回転させる 3. 射影ヒストグラムを求める 4. 正面度を求める 5. 2~4を任意の範囲で繰り返す 6. 最も正面度が高い角度を求める
正面度は、射影ヒストグラムから行の抽出しやすさになるのですが、簡単化の為に射影ヒストグラムの比の総和としました。
*正面”度”と度合いを名乗っているのに低いほうが正面という分かりにくい指標です
np.sum(hist)
以下に、回転させた画像と正面度を示します。
| 入力画像 | 角度と正面度 |
|---|---|
 |
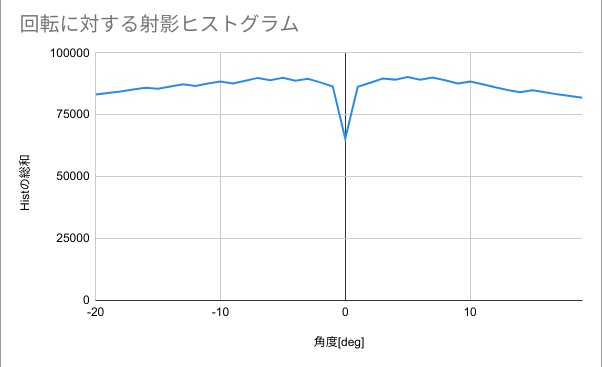 |
回転角が0°(正面)に近づくにつれて、正面度が特徴的なスパイクを形成しています。
このスパイクの頂点となる角度が文書画像が最も正面っぽく見える角度となります。
まとめ
射影ヒストグラムを用いた文書画像の回転補正を行いました。
文書画像の回転補正は、tesseractを始めとするOCRの認識精度を向上させる重要な手法です。
次はこの手法を用いて、実際にOCRをやってみたいです。